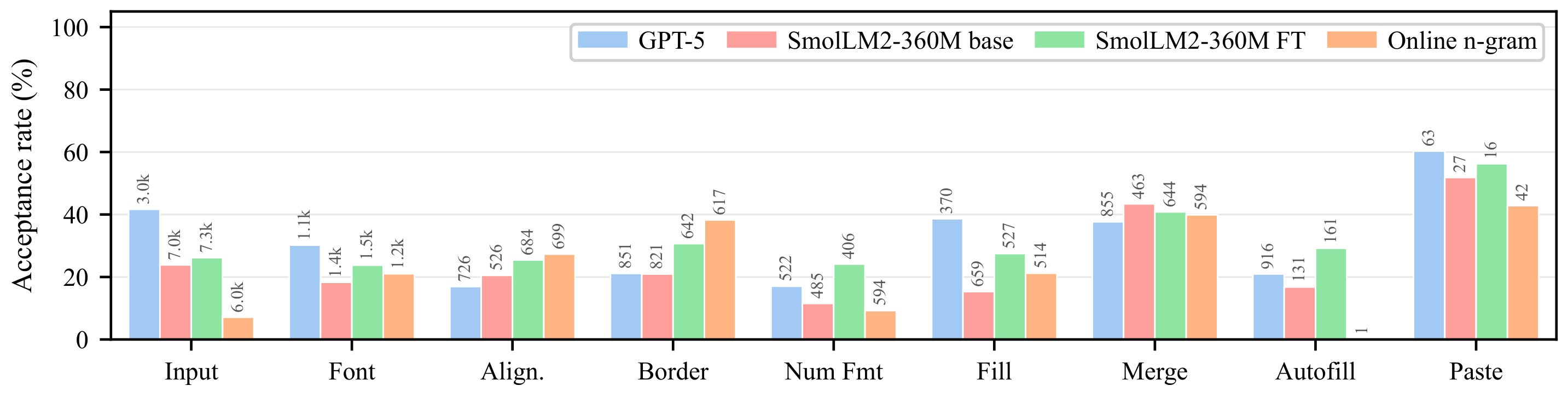
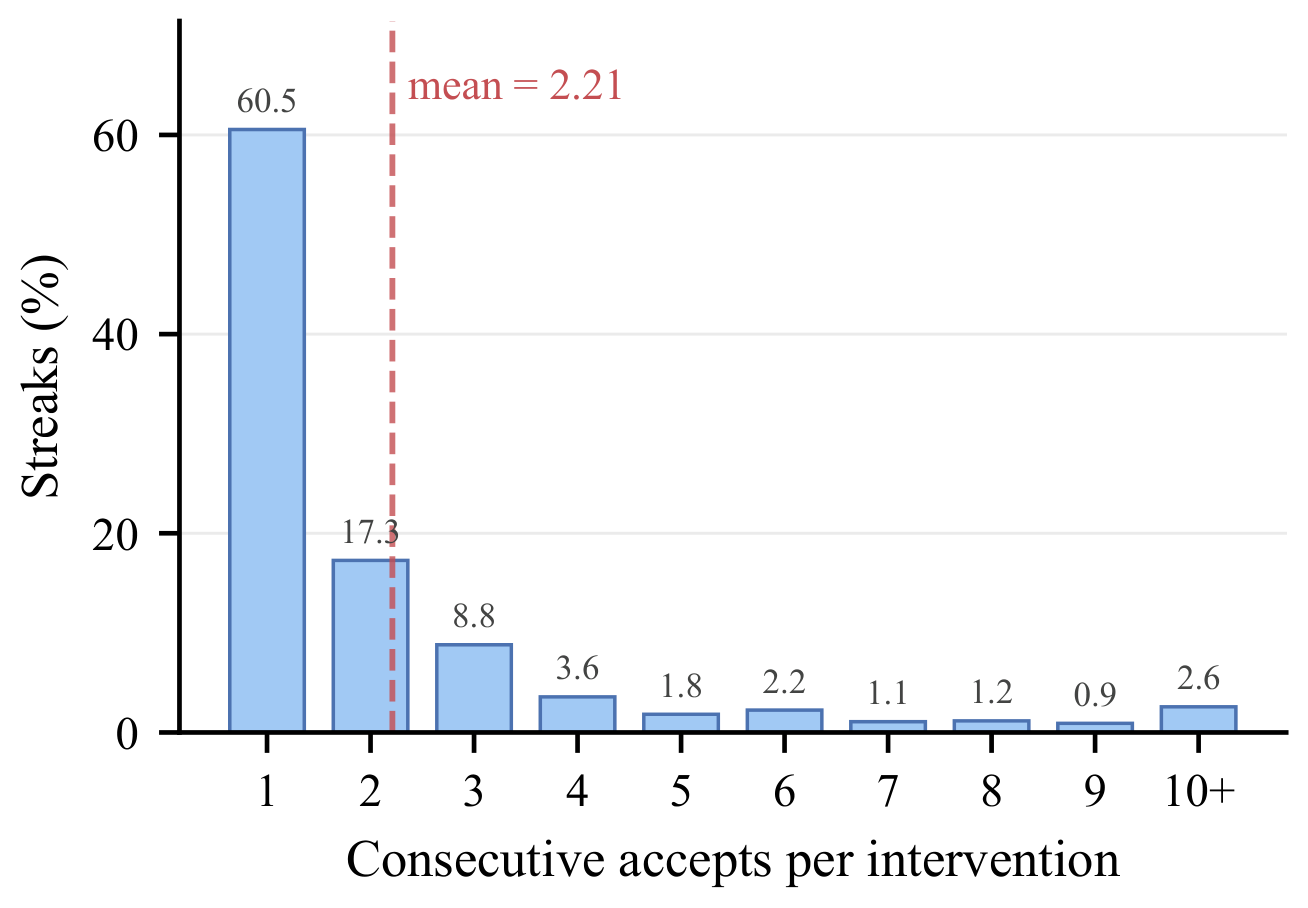
The method
Online evaluation, not “given x, predict y”
A real assistant changes the very state it operates in. We evaluate on-policy: predictions reshape the future the user still has to complete.
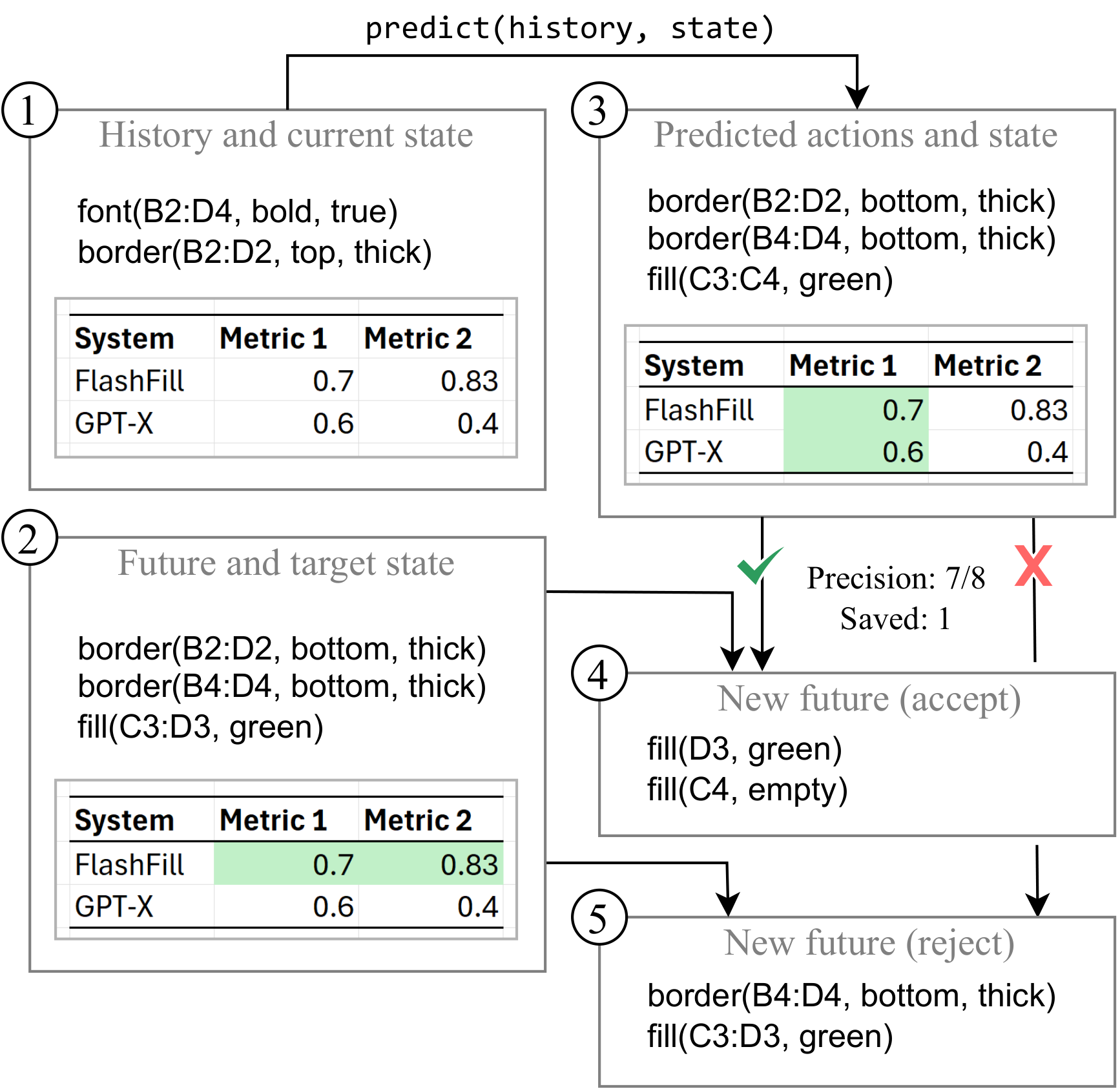
The accept & adapt loop
- Predict. After each user action the solver proposes ≥0 next actions.
- Decide. An acceptance heuristic accepts or rejects (modeling the user).
- Adapt. On accept, drop satisfied ops, prepend inverses for false positives, and patch so the target is still reached.
- Repair. The system must fix its own mistakes — impossible to capture offline.
State-level metrics
UAS % user actions saved primary
AR predictions accepted
PREC correct predicted edits
pCov of predictable edits hit
Scored on the resulting workbook state — different action sequences can reach the same sheet.
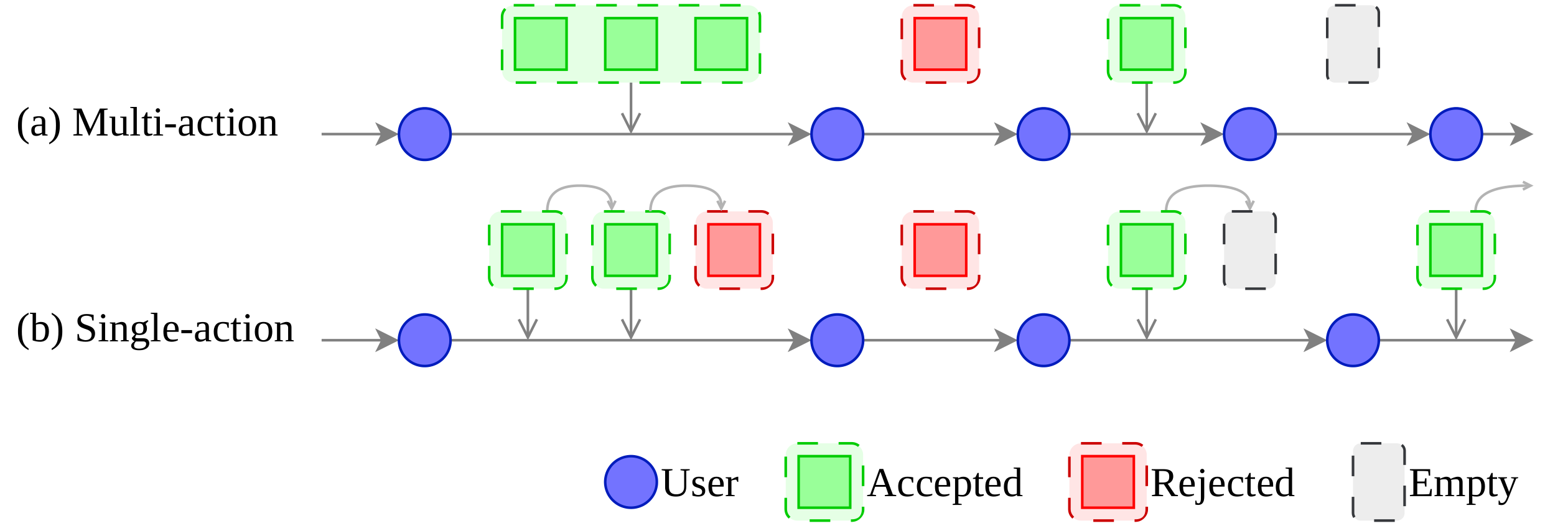
Two prediction settings
Single-action (k=1, re-predict): one op at a time, re-queried after each accept — levels the field for small models. Multi-action (k≥1): emit a whole block and advance by what's accepted — natural for LLMs.
What “actions saved” looks like
Each accepted prediction removes work the user would otherwise do. The blue line drops below the no-assist baseline; the green area is the saved effort — small on weak trajectories, large on strong ones.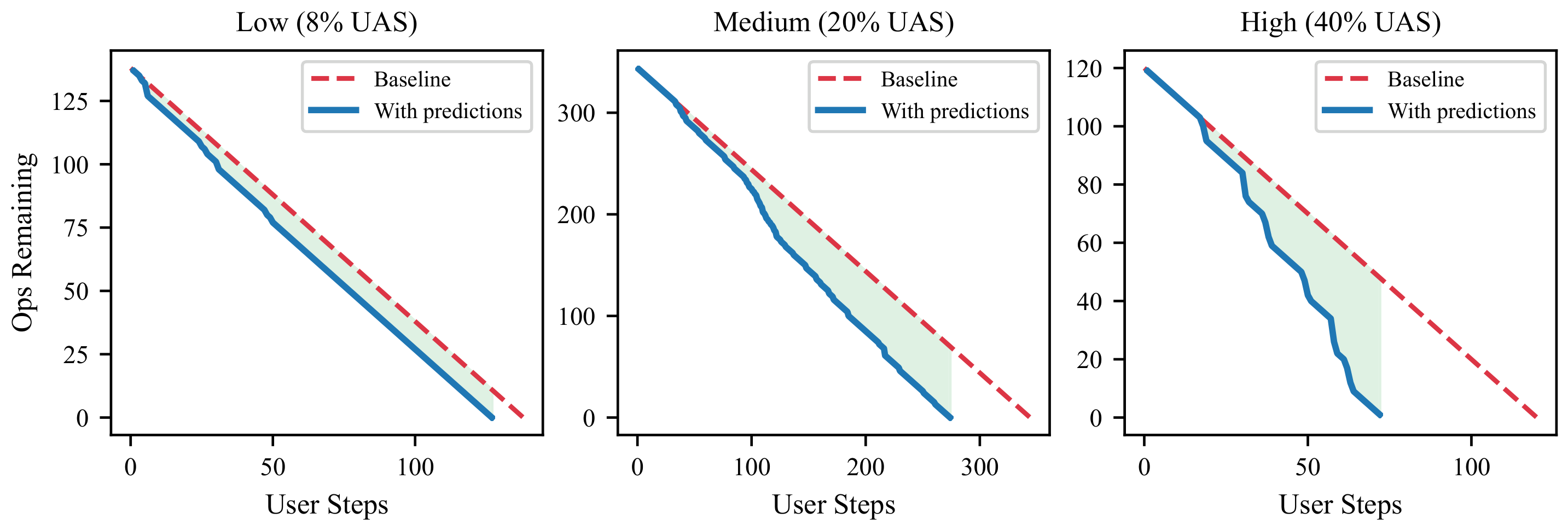
68%
How much is even predictable?
An oracle of four reasoning LLMs recovers 68% of all edits from history alone (median 66% per sheet; 44/52 sheets > 50%). This sets a ceiling on how much any predictor can save.